How I Built a "Set It and Forget It" Sync System with Django Signals
Change a product's price anywhere in your app, and it instantly syncs to a third-party marketplace. No manual triggers, no polling, no fragile save() overrides. Here's the signal pattern that powers it.
The Problem
In our app, a product's name or price can change from eight different places. The edit page. Bulk import. The variant editor. A pricing rule engine. An API endpoint that processes webhooks from suppliers. Every few weeks, someone adds a new feature and creates yet another code path that mutates a product.
We needed every one of those changes, no matter where they came from, to sync to an external marketplace. The naive approach would be to add a sync call to each code path. That's eight places to maintain (and counting), eight chances to forget, and eight places that break if the sync API changes.
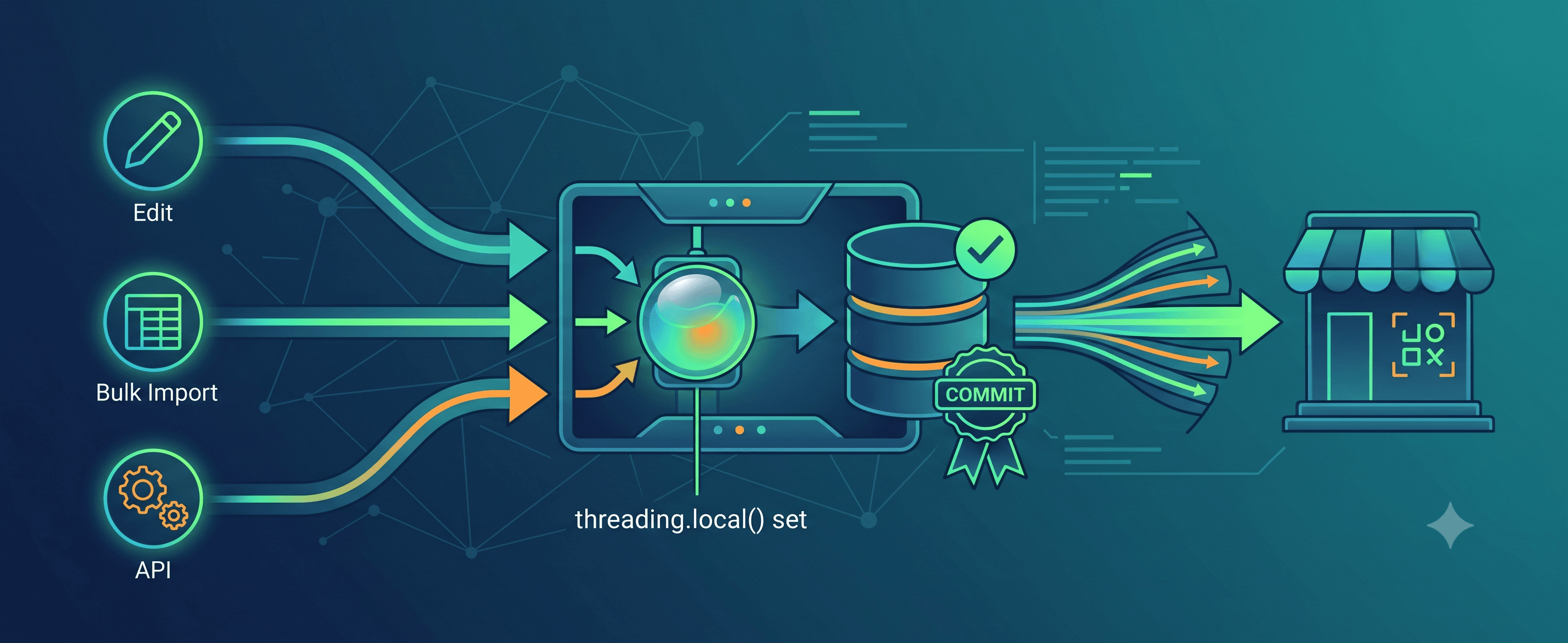
Django's post_save signals solve the discovery problem: hook into a model's save event and you catch every change, from every code path, in one place. Signals get a bad rap — fairly, they make control flow hard to trace. But when you need to react to changes from everywhere without touching anywhere, this specific discovery problem is exactly what they were designed for.
There's a catch, though. If ten prices change in a single request, say, a bulk import, a naive signal handler fires ten times. That's ten API calls in rapid succession. At best, you are wasting resources. At worst, the external API rate-limits you.
We needed signals to detect changes, but we needed to batch them.
The Solution
Here's the three-part pattern:
A signal handler that collects change references instead of acting on them immediately.
A per-thread set that deduplicates for free — adding the same product twice does nothing.
A flush callback deferred to
transaction.on_committhat processes everything once the database transaction lands.
Step 1: Register the signal
In your app's apps.py, connect post_save to the model that holds pricing:
# shopping/apps.py
from django.apps import AppConfig
class ShoppingAppConfig(AppConfig):
name = "shopping"
def ready(self):
from django.db.models.signals import post_save
from shopping.models import PriceRecord
from shopping.signals import on_price_change
post_save.connect(
on_price_change,
sender=PriceRecord,
dispatch_uid="shopping_price_change",
)
dispatch_uid prevents duplicate connections if ready() runs twice, a common gotcha during development with auto-reload.
Step 2: Collect, don't act
The signal handler doesn't call an API. It just adds a reference to a set and registers a flush callback:
# shopping/signals.py
import threading
from django.db import transaction
_local = threading.local()
def _get_pending():
if not hasattr(_local, "pending"):
_local.pending = set()
return _local.pending
def on_price_change(sender, instance, **kwargs):
# Record just enough to look up the product later
_get_pending().add(instance.object_id)
transaction.on_commit(flush_changes)
That's it. Four lines of logic. The handler doesn't care how many prices changed or where the change came from. It just records what changed and defers action to the flush.
Notice that we use threading.local() instead of a standard module-level variable. This ensures that each thread gets its own isolated storage.
Why transaction.on_commit? If the transaction rolls back, the price change never happened, so the flush callback is discarded. You never sync data that wasn't committed.
Step 3: Flush once per transaction
When the transaction lands, the flush handler fires. It snapshots the set, clears it immediately, and processes everything in one batch:
def flush_changes():
pending = _get_pending()
refs = pending.copy()
pending.clear()
if not refs:
return
from shopping.services import SyncService
SyncService.handle_price_changes(refs)
The key detail: we copy the set before clearing it. If clearing happened after processing, and processing raised an exception, stale refs would linger into future transactions. Snapshot-first is defensive.
This clear() is also what keeps requests perfectly isolated. Once a transaction commits and the flush runs, the set is empty and ready for the next request.
Step 4: Resolve and dispatch
The service layer resolves the raw references into business entities, groups them by destination, and dispatches one task per group. The grouping is the important part. One API call per store, regardless of how many products changed:
# shopping/services.py
from collections import defaultdict
class SyncService:
@classmethod
def _resolve_to_products(cls, refs: set[int]):
"""
Resolve product ID references to actual Product instances
with their Store relationship. Fetches everything in ONE
query using filter(id__in=...), silently ignoring stale
IDs that no longer exist.
"""
products = Product.objects.filter(
id__in=refs
).select_related("store")
resolved = []
for product in products:
resolved.append((product, product.store_id))
return resolved
@classmethod
def handle_price_changes(cls, refs: set[int]):
resolved = cls._resolve_to_products(refs)
# Group changes by the store they belong to
by_store = defaultdict(list)
for product, store_id in resolved:
by_store[store_id].append(product)
# One API call per store, regardless of how many products changed
for store_id, products in by_store.items():
sync_to_marketplace.delay(store_id=store_id, products=products)
The sync_to_marketplace task is a Celery task that calls the external API. It's configured with retries and backoff for transient failures:
@shared_task(bind=True, max_retries=3, default_retry_delay=60)
def sync_to_marketplace(self, store_id, products):
try:
provider.bulk_update(store_id, products)
except Exception as exc:
raise self.retry(exc=exc)
Why This Works
Deduplication is free. A set naturally deduplicates, adding the same object_id twice is a no-op. If a price changes twice in the same request (say, a pricing rule recalculates it), the flush handler sees it once. And when it fires, it reads the latest price from the database. The most recent value always wins.
Transaction safety is built-in. transaction.on_commit guarantees the flush only runs after the database confirms the change. If the transaction rolls back (a validation error, a constraint violation, a raise somewhere), the callback is discarded. You never sync phantom data.
Batch resolution avoids N+1. The service resolves all references in bulk queries, not one at a time. For 50 changed products, it takes exactly 1 query regardless of count. No per-product lazy loading.
Design Decision: Avoiding the Global State Pitfall
You might be wondering why we used threading.local() in Step 2 instead of a simple module-level variable like _pending_changes = set().
A basic module-level set shares state across every request handled by the same worker process. If User A's request rolls back, stale refs from their failed transaction sit in the global set. When User B's request commits ten minutes later on the same worker, the flush accidentally picks up both User A's and User B's products.
By using threading.local(), we protect against this cross-request leakage. Even if a transaction rolls back, any leftover references in that thread's set will simply be cleared on its next successful commit. And in the rare event a stale reference makes it to the resolver, it evaluates to nothing and is skipped silently.
One thing to watch for: use .filter() when looking up products in your resolver, not .get(). .filter() returns an empty queryset gracefully. .get() throws DoesNotExist and tanks your flush.
The Result
The user experience is deceptively simple. A user toggles "Sync product prices" on a store configuration page. From that moment on, any price change from any code path in the application syncs to the external marketplace within seconds.
No one has to remember to add a sync call to new features. No one has to track down every place a price can change. No one monitors a queue for failures (Celery retries handle that). The system just works.
How are you handling external API syncs in your Django apps? Are you using signals, or do you prefer a different pattern? Drop your approach in the comments.
¡Hasta luego!



